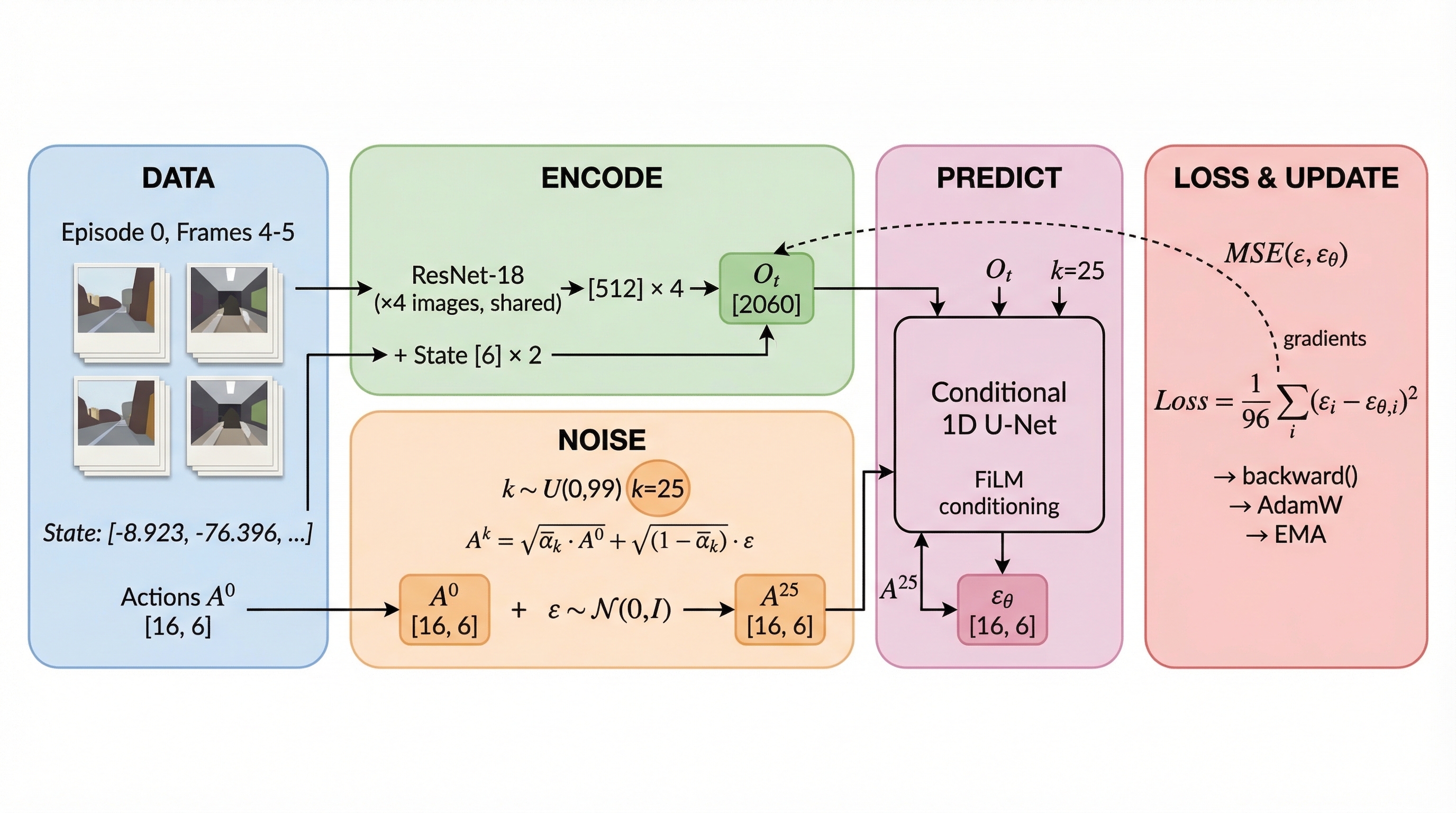
We pick one concrete example — Episode 0, frames 4 & 5 — and trace it end-to-end through every step of the training pipeline with real numbers.
Live Data: so101_pick_place_red_cube • Episode 0 • Frames 4–5
Scroll to begin ↓
0
Your Dataset
10 teleoperation demonstrations of an SO-101 robot picking and placing a red cube
10
Episodes
9,219
Total Frames
30
FPS
6
DOF Joints
2
Cameras
640×480
Resolution
Front Camera
observation.images.front
Side Camera
observation.images.side
We'll trace one training example through the entire pipeline: Episode 0, frames 4 & 5 (timestamps 0.133s and 0.167s). Every number you see below comes from this exact data point.
1
Here Are Your Two Observation Frames
The policy sees exactly To = 2 frames: frame 4 (t−1) and frame 5 (t) from Episode 0
Front Camera — observation.images.front
These are the actual camera images the robot saw. Two consecutive frames give the network a sense of motion.
Frame 4 (t−1) — t = 0.133sot-1
Frame 5 (t) — t = 0.167sot
Side Camera — observation.images.side
Frame 4 (t−1) — t = 0.133sot-1
Frame 5 (t) — t = 0.167sot
Two cameras × two timesteps = 4 images total feeding into the vision encoder. Each image is [480, 640, 3] RGB.
st = [-9.099, -76.396, 77.758, 6.549, 122.945, 6.560]
Concatenated state input:
[st-1, st] → 12 values total (6-dim × 2 frames)
Between frames 4→5 (33ms apart), the shoulder pan, elbow, and wrist flex are moving — the robot is adjusting its arm. The shoulder lift, wrist roll, and gripper are stationary. Two frames give the network a sense of velocity.
3
Here Are the 16 Actions to Predict
The prediction horizon Tp = 16 — starting at frame 5, these are the next 16 target joint positions
Action Chunk A&sup0; — Shape: [16, 6]
In this early phase of Episode 0, the robot is converging to its initial position. All 16 actions are identical — the teleoperator's leader arm is holding steady. This is A&sup0; — the clean action trajectory before any noise is added.
Step
Shoulder Pan
Shoulder Lift
Elbow Flex
Wrist Flex
Wrist Roll
Gripper
Why Are They All The Same?
At the very start of a teleoperation episode, the operator positions the leader arm and waits. The action column records the leader's (target) position at every frame. Since the leader isn't moving yet, frames 0–59 all have the same action: [-10.374, -81.670, 77.846, 2.681, 123.209, 6.495]. Later in the episode, the actions diverge as the robot begins its pick-and-place motion.
# Extract T_p=16 consecutive actions starting at frame 5
action_chunk = []
for i inrange(16):
idx = min(5 + i, len(episode) - 1)
action_chunk.append(episode[idx]['action'])
A_0 = torch.stack(action_chunk) # shape: [16, 6]# All 16 rows are [-10.374, -81.670, 77.846, 2.681, 123.209, 6.495]
4
Passing Images Through the ResNet Encoder
4 images go through a modified ResNet-18 with SpatialSoftmax → 4 × [64] feature vectors → concatenate with state
Architecture Overview
Tracing Real Pixel Values — Front Camera, Frame 5 (t)
Let's trace actual pixel values from the frame we extracted in Step 1. We sample the center pixel and show what happens at each processing stage.
Sampled Pixel (center of frame)
Red crosshair shows the sampled pixel location (320, 240)
RGB Values at (320, 240)
Loading pixel values from video frame...
Step-by-Step: Real Numbers Through Each Layer
Here's what happens to our front camera frame (t=0.167s) as it passes through each ResNet layer. We show the tensor shape at each stage, and for the first two stages, the actual numerical values at our sampled pixel.
Input (raw frame)
[3, 480, 640]
pixel[320,240] = [R, G, B] (loading...)
↓
Resize + CenterCrop
[3, 76, 76]
480×640 → scale to 76×101 → center crop to 76×76.
pixel values preserved (nearest-neighbor or bilinear)
The same shared-weight ResNet-18 + SpatialSoftmax processes all 4 images (2 cameras × 2 timesteps). Each produces a [64] vector (32 keypoints × 2 coords). These are concatenated with the two state vectors from Step 2.
Why SpatialSoftmax Instead of Global Average Pooling?
Standard ResNet-18 uses AdaptiveAvgPool which discards all spatial information. For robot manipulation, where objects are matters just as much as what they are. SpatialSoftmax learns 32 keypoints — each one a (x, y) coordinate localizing a salient feature in the image. This preserves spatial structure in a compact 64-d vector. GroupNorm replaces BatchNorm because robot learning uses small batch sizes: GroupNorm(num_features // 16, num_features).
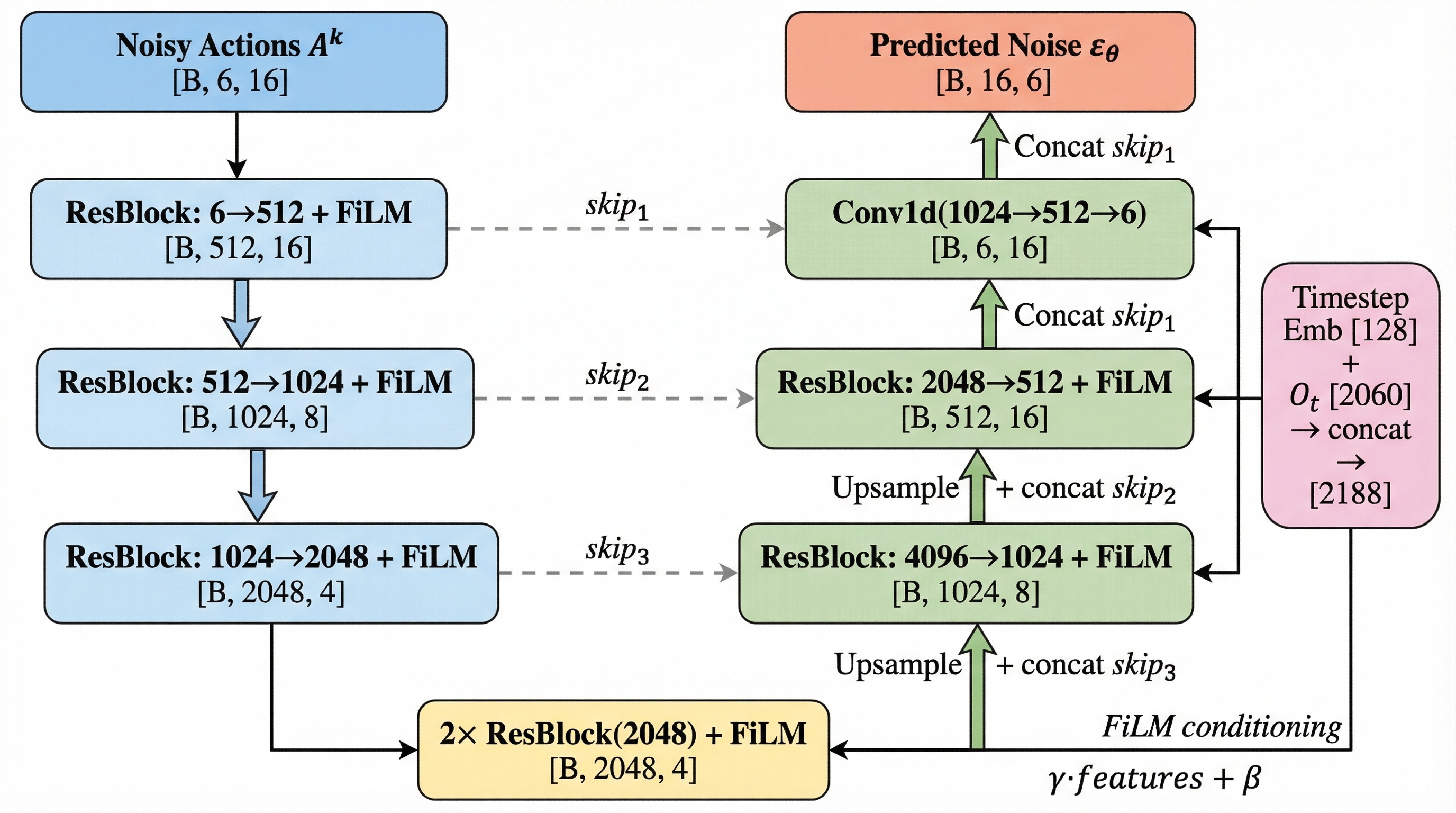
FiLM means the network doesn't just see the observation — it modulates how it processes the noisy actions at every layer. "Given what I see and which noise level we're at, here's how to denoise."
classConditionalUnet1D(nn.Module):
def__init__(self, input_dim=6, global_cond_dim=268,
down_dims=[256, 512, 1024],
diffusion_step_embed_dim=256):
# Total cond dim = 256 + 268 = 524# Encoder: 6→256→512→1024# Decoder: 1024→512→256→6
...
defforward(self, sample, timestep, global_cond):
# sample: [B, 16, 6] → [B, 6, 16]
x = sample.permute(0, 2, 1)
# Timestep embedding
t_emb = self.diffusion_step_encoder(timestep) # [B, 256]
cond = torch.cat([t_emb, global_cond], dim=-1) # [B, 524]# Encoder with FiLM
skips = []
for resblock, downsample in self.down_modules:
x = resblock(x, cond) # FiLM: Linear(524→2*ch)
skips.append(x)
x = downsample(x)
# Bottleneck
x = self.mid_modules(x, cond)
# Decoder with skip connectionsfor resblock, upsample in self.up_modules:
x = upsample(x)
x = torch.cat([x, skips.pop()], dim=1)
x = resblock(x, cond)
x = self.final_conv(x) # [B, 6, 16]return x.permute(0, 2, 1) # [B, 16, 6]
8
Computing the Loss & Gradient Update
Compare predicted noise to actual noise, compute MSE, and update all weights
Actual Noise ε vs Predicted Noise εθ (Joint 0 across 16 timesteps)
Blue = the actual Gaussian noise ε we sampled in Step 5. Coral = what the U-Net predicted. Early in training, these are very different.
ResNet-18 weights All conv layers, GroupNorm layers
Weight Update
AdamW step:θnew = θold − lr × m̂/(√v̂ + ε) − lr × λ × θold
Learning rate:1e-4
EMA update:θema = 0.9999 × θema + 0.0001 × θnew
The EMA (Exponential Moving Average) model is a smoothed copy of the weights used at inference time. It prevents the deployed policy from being affected by noisy gradient updates.
Training Hyperparameters
Parameter
Value
Optimizer
AdamW (betas = 0.95, 0.999, weight_decay = 1e-6)
Learning Rate
1e-4 with cosine annealing + 500-step warmup
Batch Size
64
Epochs
3000
Diffusion Steps
100 (train) / 10 (DDIM inference)
EMA Decay
power=0.75, max=0.9999
Prediction Horizon Tp
16
Observation Horizon To
2
Action Execution Ta
8 (receding horizon at inference)
# One training iteration — the complete pipeline from this walkthroughfor batch in dataloader:
# Steps 1-2: Extract observations (4 images + 2 state vectors)
obs = batch['obs']
A_0 = batch['action'] # [B, 16, 6] — Step 3# Step 4: Encode observations → global conditioning
O_t = obs_encoder(obs) # [B, 268]# Step 5: Sample noise and random timestep
eps = torch.randn_like(A_0)
k = torch.randint(0, 100, (B,))
A_k = scheduler.add_noise(A_0, eps, k)
# Steps 6-7: U-Net predicts noise
eps_theta = unet(A_k, k, global_cond=O_t) # [B, 16, 6]# Step 8: MSE loss + backprop + update
loss = F.mse_loss(eps_theta, eps)
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step()
ema_model.step(model.parameters())
✓
That's One Training Iteration
Everything you just saw — from raw camera frames to gradient update — happens once per batch element, thousands of times
Complete Pipeline — One Training Iteration
At Inference Time (After Training)
The process runs in reverse: start with pure Gaussian noise AK ~ N(0, I), then iteratively denoise for K steps (or 10 DDIM steps for 10x speedup). At each step, the trained U-Net predicts the noise to subtract, conditioned on the current observation Ot. The result is a clean 16-step action trajectory. Only the first Ta = 8 actions are executed before replanning — this receding horizon approach balances temporal consistency with responsiveness.
![ResNet-18 Encoder Architecture — 4 images through shared-weight ResNet-18 with SpatialSoftmax to Global Conditioning Vector [268]](images/resnet_encoder_diagram.png)